Auto ML
Build thousands of models with the click of a button.
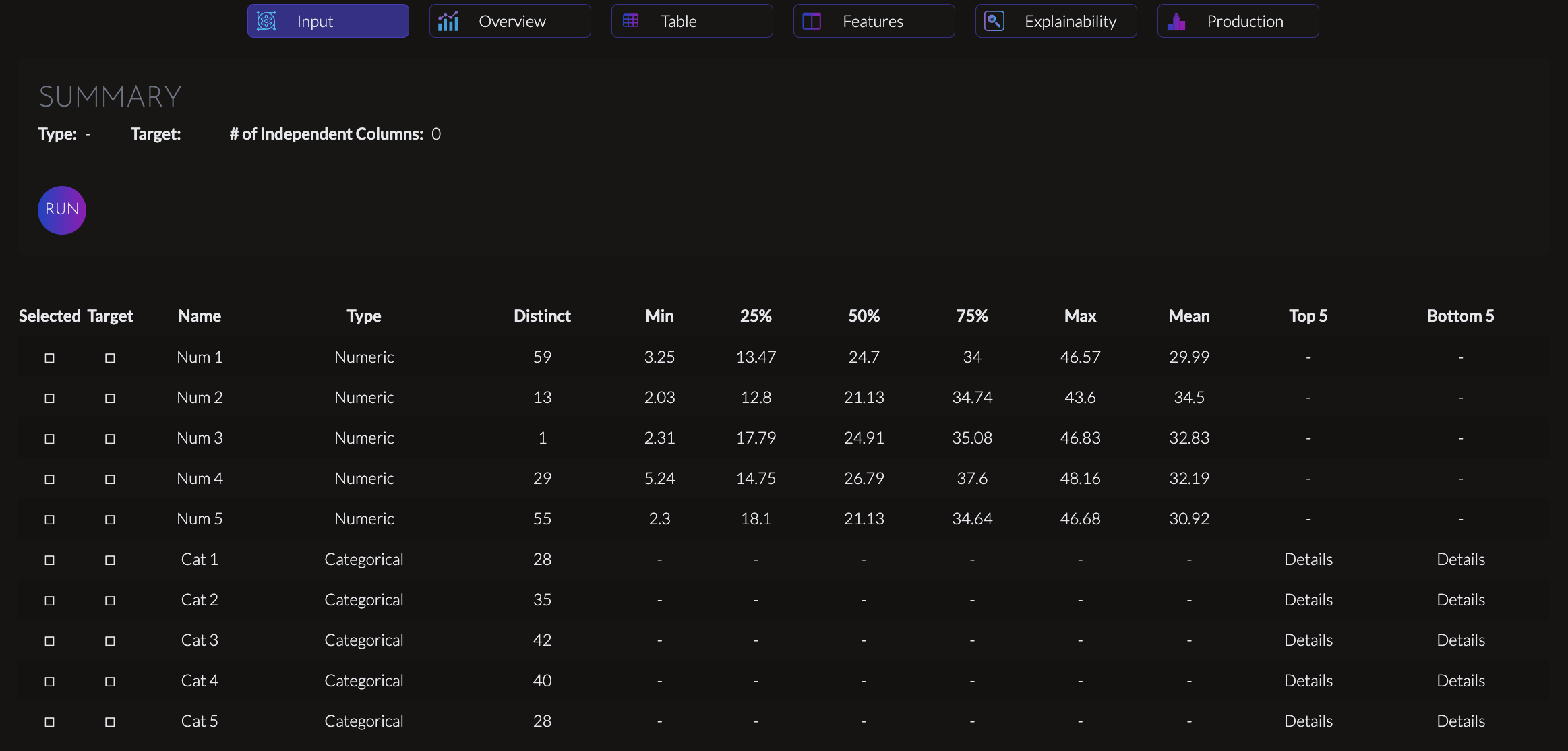
Inputs & Lifecycle

-
Select the target
- Designate the column that you want to predict
-
Feature Selection
- Select the columns that you belive will help predict the target
- Select a flag if you want a feature selection step to reduce the number of columns to a more optimal level.
-
Parameter Search
- For each model, hundred of parameters will be fit using a randomized search
-
Model Evaluation
- Models will be compared to identify the best fit based off a standardized
(e.g.
R^2) or custom metrics
- Models will be compared to identify the best fit based off a standardized
(e.g.
Optional Arguments
-
Feature Selection
- Identifies the best columns to use.
- We will take all the columns and narrow those down to the best columns for the model. By default, this is turned on and is a standard step in the machine learning lifecycle.
- Identifies the best columns to use.
-
Shuffle
- Arranges the rows of the data in a different order.
- Do not use this if the data is time series (i.e., lagged data is being used to predict the dataset). Alternatively, for non-time-based data, this is often a helpful feature that improves results.
- Arranges the rows of the data in a different order.
-
Test Size
- Sets the percentage of data that will not be used for training.
- A higher test size often results in a model that has lower training scores, but generalizes to unseen data better. Lower test sizes are more easily overfit, but they can result in better models due to seeing more data.
- Sets the percentage of data that will not be used for training.
-
Scaler
- The Standard Scaler standardizes features by removing the mean and scaling to unit variance. The Min-Max Scaler scales features to a given range, typically between 0 and 1.
- The Standard Scaler transforms data to have zero mean and unit variance, making it suitable when the distribution of the features is not known. On the other hand, the Min-Max Scaler scales the data to a specific range, preserving the original distribution and is useful when the feature range needs to be preserved.
- The Standard Scaler standardizes features by removing the mean and scaling to unit variance. The Min-Max Scaler scales features to a given range, typically between 0 and 1.
-
Imputer
- The Simple Imputer provides basic imputation techniques such as mean, median, or constant value imputation, while the KNNImputer uses k-nearest neighbors algorithm to impute missing values based on similar data points.
- The Simple Imputer is useful for imputing missing values with simple statistical measures, while the KNNImputer is more flexible and suitable when there is a complex relationship between the missing values and other features, as it considers the neighboring data points for imputation.
- The Simple Imputer provides basic imputation techniques such as mean, median, or constant value imputation, while the KNNImputer uses k-nearest neighbors algorithm to impute missing values based on similar data points.
-
Number of Iterations
- Refers to the number of iterations or loops performed during an algorithm or process.
- Indicates the number of times the model tries to improve itself. Higher numbers result in longer training times, but potentially better models.
- Refers to the number of iterations or loops performed during an algorithm or process.
-
K-Fold
- The available dataset is divided into k equally sized folds or subsets.
- Partitions the dataset into k parts, typically for the purpose of training and evaluating a model. The data is divided into k subsets, and in each iteration, one of the subsets is used as the validation set while the remaining k-1 subsets are used as the training set.
- The available dataset is divided into k equally sized folds or subsets.
-
Number of Parameter Samples
- The number of times a different number of parameters will be used to fit the model.
- Determines how many different combinations of parameter values will be tried during the search. It helps in finding the best combination of parameter values for a machine learning model by exploring a subset of all possible combinations.
- The number of times a different number of parameters will be used to fit the model.
Models by Problem Type
Regression Models
- Linear Regression
- Support Vector Regressor
- Random Forest Regressor
- Gradient Boosting Regressor
- Neural Network
Classification Models
- K-Neighbors Classifier
- Support Vector Classifier
- Decision Tree Classifier
- Random Forest Classifier
- MLP Classifier
- Ada Boost Classifier
- Gaussian NB
- Quadratic Discriminant Analysis